На вашем сайте может быть несколько страниц с одинаковым контентом, к примеру, так случается, когда на одной выставлен фильтр по цене, а на другой по модели, цвету или размеру. Тем не менее поисковые системы не видят в них разницы и могут посчитать за дубли. Чтобы этого избежать нужно выделить главную страницу среди остальных – это и будет каноническая страница.
В этом материале расскажем о том, что такое rel=“canonical”, когда нужно указывать данный атрибут, как это сделать и как избежать распространенных ошибок. Этот материал будет интересен начинающим SEO-оптимизаторам и тем, кто хочет освежить свои знания, ведь нюансов действительно много.
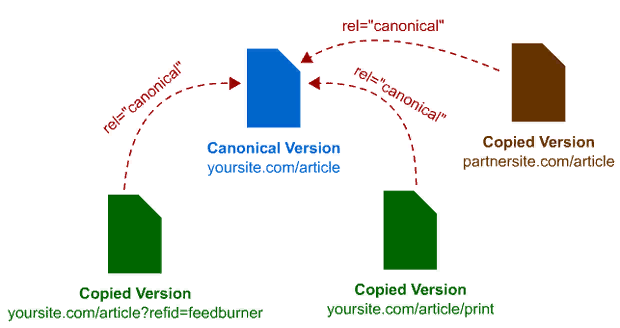
Что такое rel=“canonical” и для чего он нужен
Еще раз напомним, что одинаковый контент зачастую вполне оправдан. Условные дубли могут появляться, если одна и та же страница входит в несколько категорий, если сайт доступен в версиях с «www» и без, а также в каталогах с сортировкой (подробнее обо всех ситуациях расскажем ниже). При этом страницы могут быть не на 100 % одинаковыми, но даже включенный фильтр, к примеру, не делает их и уникальными. По крайней мере таковыми их видят поисковые боты. А за дубли они вполне могут наложить санкции и создать проблемы при появлении страниц в выдаче.
Каноническая страница — это основной, выделенный вами URL. При индексации робот будет считать такую страницу главной, а остальные похожи – дублями. Прописать каноническую страницу можно с помощью специального атрибута rel=»canonical». Данный тег добавляется на страницы-дубли с указанием HTMадреса канонической страницы. Таким образом, поисковые роботы будут знать, какая страница повторяется.
Пример, как правильно использовать canonical
Допустим, есть несколько страниц с одинаковым контентом, расположенных по адресам:
site.ru/page?id=789
site.ru/blog/category/tovar
site.ru/blog/Tovar
Из них мы выбираем одну «site.ru/blog/category/tovar» для ранжирования в выдаче. Она останется в неизменном виде и будет считаться канонической. На нее будет падать весь ссылочный вес, трафик и другие сигналы. А вот в коды дублей нужно будет добавить строчку:
<link rel="canonical" href="http://site.ru/blog/category/ tovar"/>
Еще один пример того, как можно и нельзя прописывать атрибут rel=»canonical»:

Зачем указывать основную версию страницы?
Основная причина использовать каноникал – минимизация риска попадания сайта под санкции из-за дублирования контента. Однако есть еще несколько не менее важных:
- корректность передачи ссылочного веса на выбранную страницу или версию сайта;
- выбор страницы, которая будет показываться в выдаче и получаться все сигналы;
- оптимизация краулингового бюджета (он не будет тратиться на дубли).
Более подробно о канонических ссылках и их назначении можно почитать в справках Google и Яндекса.
Есть ли шанс, что неканонические страницы все-таки попадут в выдачу?
Яндекс отвечает на этот вопрос так: такие страницы могут быть показаны при условии, что они более релевантны запросу, и их контент все-таки сильно отличается от того, что расположено на канонической странице в момент сканирования. Чтобы проверить, попадали ли неканонические страницы в выдачу Яндекса, нужно зайти в Вебмастер, открыть «Страницы в поиске» и поискать среди них строчку с пометкой «Неканоническая».
По версии Google система признает канонические URL, но это тоже работает не в 100 % случаев, так как атрибут canonical является рекомендательным, это не прямой приказ к действию. Если во время сканирования неканоническая страница покажется более релевантной, она и появится в выдаче.
Есть ли тогда смысл указывать тег? Определенно, да. Таким образом снижается риск, что в спорной ситуации поисковая система определит не ту версию страницы в качестве основной, а это грозит проблемой при индексировании страниц. Ниже рассмотрим ситуации, когда тег canonical точно нужен.
Когда стоит прописать канонический тег
Использовать canonical нужно обязательно в следующих случаях:
- если одинаковый контент размещен на разных URL;
- если дублирующиеся URL создаются системой, при этом контент не повторяется.
Во втором случае несколько URL обслуживают одно содержимое, но все равно они считаются за дубли, поэтому тег точно понадобится. Разберемся во все подробнее.
Дублирование страниц, которые генерируются CMS
Это считается нормальным явлением для интернет-магазинов, где большое количество карточек товаров, и пользователь может настраивать параметры выбора. Таким образом, образуются самые разные страницы: навигация по каталогу, сортировка и фильтрация товаров (по цвету, размеру, цене и проч.), ссылки с UTM-метками, а также иные страницы с GET-параметрами в URL.
Например, в интернет-магазине есть несколько позиций одной куртки. Отличия только в размере. В этом случае можно выбрать наиболее популярный, и эту страницу отметить в качестве канонической. Все доступные варианты курток пользователи будут видеть без изменений, но ссылочный вес и другие сигналы будут направляться на страницу, выбранную основной. Еще одна ситуация – каталожная страница подходит под несколько категорий. Таким образом, появляются множественные URL одного товара. Здесь нужно будет выбрать наиболее популярную страницу и прописать ее в дублирующих с помощью rel=»canonical».
Страницы пагинации
Из-за переключения страниц в каталоге появляются дубли. Зачастую для всех страниц пагинации в качестве канонической указывается именно первая, но это не совсем рациональное решение. В таком случае индексироваться будет только она. Как выйти из данной ситуации без потерь? Рассмотрим несколько вариантов:
- Если есть пометка «Показать все». Основная страница со всеми ее вариациями будет канонической. На каждой из страниц пагинации нужно указать основную в атрибуте rel=»canonical».
- Если нет пометки «Показать все». Здесь рекомендуется указать каждую страницу пагинации как каноническую.
- Указать canonical страницы саму на себя. В этом случае все страницы пагинации появятся в выдаче. Но есть мнение, что у разных URL с разным контентом не должно быть одинаковых Title и Description. Тогда canonical лучше не проставлять. Страницы пагинации нужно будет закрыть в noindex, follow и использовать директиву disallow в robots для /page. Важно учитывать, что этот вариант работает только для Яндекса.
Страницы с HTTPS, HTTP, www в URL
Один и тот же сайт может иметь 3 варианта написания URL: с HTTPS, HTTP, www. Но для поисковых систем это выглядит как три набора отдельных страниц. Если не указать canonical, могут возникнуть проблемы при сканировании и индексации сайта.
Наличие мобильной версии сайта
Уже некоторое время назад Google при индексировании стал ориентироваться на мобильную версию сайта (Mobile-First Indexing). Как тогда быть с каноническим тегом? На этот вопрос ответил Джон Мюллер – представитель Google. По его словам, обычно у мобильной версии указывается rel=»canonical», который ведет на десктопную. В то же время у десктопной прописывается тег rel=alternate, который ведет на мобильную версию. Если все сделано изначально по данной схеме, то ничего менять не понадобится – робот и так сможет определить мобильную версию в качестве канонической.
Сайты с URL разных стран
Множество сайтов имеют несколько версий для разных стран, с адаптированными под это URL. При этом на таких ресурсах может быть практически один и тот же контент на одном языке лишь с небольшими отличиями. В таком случае нужно обязательно указать канонические страницы и сделать отсылки ко всем имеющимся дублям. Если же контент на сайтах представлен на разных языках, необходимо использовать атрибут hreflang. С его помощью указываются дополнительные URL с аналогичным или похожим контентом, но на другом языке. Благодаря этому атрибуту поисковики смогут выдавать отдельные результаты. Но здесь нужно снова вспомнить о Mobile-First Indexing от Google. Из-за перехода на него требуется правильная настройка hreflang. Так, десктопные теги должны ссылаться на десктопные URL, а мобильные на мобильные.
Учет верхнего и нижнего регистров в URL
Для поискового робота два адреса, которые написаны в разном регистре, зачастую являются разными. При назначении URL системой должен использоваться только нижний регистр. Это делается для того, чтобы одни и те же ссылки выглядели действительно одинаковыми.
6 способов настроить canonical правильно
Как мы уже выяснили, rel=»canonical» позволяет указать главную страницу среди дублей для корректной индексации, появления правильной страницы в выдаче и направления на нее ссылочного веса. Но чтобы это произошло, нужно правильно настроить тег.
В общих чертах процесс выглядит просто: необходимо выбрать основной URL среди дублей, вписать его в атрибут и добавить ко всем неосновным страницам. Сделать это можно несколькими способами, актуальными для разных ситуаций. Рассмотрим их подробнее.
1. С использованием плагина CMS
У многих CMS есть встроенная функция или плагины, позволяющие производить настройку канонической страницы в автоматическом режиме.
Несколько примеров таких настроек:
- на WordPress настроить canonical можно с помощью Yoast SEO;
- в OpenCart можно задать SEO URL в настройках товара;
- в Joomla версии от 3 и далее есть функция SEF, при включении которой в код технических страниц добавится атрибут canonical с указанием основной страницы с ЧПУ; также здесь можно использовать плагин Canonical Url;
- в 1С‑Bitrix можно использовать «Канонические ссылки»;
- в Тильде тег canonical по умолчанию проставляется сам на себя, но вы можете изменить значение атрибута вручную.
WordPress по праву считается наиболее популярной CMS, поэтому на его примере рассмотрим настройку canonical более подробно. Тут все просто:
- установить плагин Yoast SEO для автоматического добавления тегов;
- настроить теги для каждой страницы в разделе «Дополнительно» (указать основной URL).
Данный плагин «убирает» тег canonical, если на странице появляется noindex или nofollow. Это позволяет избежать проблем с представлением ресурса в выдаче.
2. Вставка атрибута rel=»canonical» между тегами любой HTML-страницы
Атрибут прописывается в коде в теге <link> в секции < head > любой страницы-копии. Данный метод допустим только для HTML‑страниц, он не будет работать с файлами (например, PDF). Хотя и для них есть свой способ. Расскажем о нем ниже.
3. Вставка атрибута в заголовок HTTP
Предыдущий способ не подходит для не HTML-документов (PDF, DOC, XLS и др.), так как у них нет секции < head >. Тем не менее вопрос решается легко, если у вас есть доступ к настройкам сервера. В этом случае атрибут canonical можно указать в заголовке HTTP, используя .htaccess или PHP. Так, при запросе дублирующего файла сервер будет отдавать ссылку на основной файл. Выглядит это так:
link:<ссылка на каноническую страницу>;rel="canonical"
4. В файле Sitemap
В XML-карте сайта по умолчанию все страницы считаются каноническими. У Google даже есть отдельное требование для этого. Поэтому и поисковые роботы воспринимают все ссылки в XML-файле как канонические (наличие дубликантов в карте сайта приведет к путанице и некорректной индексации). Поэтому просто прописывайте канонические страницы без использования дополнительных атрибутов.
5. Через 301 редирект
Он также помогает перевести ссылочный профиль, трафик и авторитетность на каноническую страницу с дублей. Данный способ рекомендуется использовать, если один и тот же сайт доступен по разным адресам: с https, http, www и без. В качестве основного можно, например, выбрать сайт с таким написанием https://site.ru/, а с остальных сделать перенаправление с помощью 301 редиректа. Напомним, что 301 редирект сообщает о том, что ресурс навсегда перемещен на новый URL.
Но здесь важно учитывать одну особенность индексации в Google. Если не соблюсти все правила и что-то упустить в настройке, поисковые роботы могут не дойти до конечной страницы и не проиндексировать ее. Поэтому нужно обязательно прописывать канонический тег, использовать внутренние ссылки, а также при необходимости тег hreflang. Последний нужен для конечной страницы, не ставьте его на ту, с которой перенаправляете пользователя.
6. Использование ссылок в качестве дополнительного сигнала
Возвращаясь к Google, стоит также сказать, что он использует разные сигналы для определения канонического URL. Например, между двумя адресами с HTTPS и HTTP он выберет HTTPS. Так же у него есть свой «взгляд» на наиболее привлекательный URL. В список сигналов можно включить ссылки с одной страницы на другую. Но не стоит забывать, что каноникализация носит лишь рекомендательный характер для Google. Если вы указываете основной одну страницу, а Google по совокупности факторов считает по-другому, то «слушать» вас он не будет.
Очень важно не допускать ошибок ни на каком из этапов настройки. О том, какими они могут быть, поговорим ниже.
Неправильно указан canonical: распространенные ошибки в настройке
Рассмотрим разные варианты ошибок, которые допускают не только новички.
Несколько канонических ссылок для одной страницы. Всегда нужно строго следовать правилу: одна страница – один канонический адрес. Если их будет насколько поисковый робот или обратиться к первому указанному URL, или вообще проигнорирует страницу. Особое внимание нужно обратить на то, как реализует canonical плагин CMS. Неправильная настройка может привести к тому, что будет указано несколько адресов.
Ошибки из-за использования сразу нескольких способов настройки canonical. Этот пункт похож на первый, однако речь не о нескольких канонических URL для одной страницы. Они разные и указаны разными способами. К примеру, вы можете вставлять канонический тег в HTTP-заголовок и секции < head >, но учитывайте, что адрес основной страницы должен быть одним и тем же.
Использование цепочки канонических URL. Поисковый робот не считает страницу основной (даже при соблюдении всех правил), если для нее прописана еще какая-то своя каноническая страница.
Размещение атрибута за пределами секции head. Для корректной работы тег canonical может находиться только в секции < head >. Если же он указан в < body > документа, поисковые роботы его просто не заметят. Они могут даже проигнорировать всю страницу. Не стоит надеяться, что изначально все заполнено правильно и атрибут никуда не сместился, лучше проверить. Даже если canonical прописан в начале документа, это не защищает от того, что секция < head > может закрыться раньше. Так, иногда происходит из-за вставок JavaScript, незакрытых парных тегов, контейнеров < iframe >. В таких случаях canonical оказывается в секции < body >. А про эту проблему мы как раз писали выше.
Выбор первой страницы пагинации в качестве канонической. Мы уже говорили о том, что если указать первую страницу пагинации канонической, то поисковый робот не проиндексирует остальные. Корректную настройку можно произвести тремя способами:
- если есть страница «Показать все», сделать ее канонической;
- если нет общей страницы, поставить URL каждой страницы в качестве канонической;
- не ставить вообще канонический тег и закрыть страницы от индексации, в файле robots использовать noindex, follow для страниц пагинации, а для /page указать директиву disallow.
Последний вариант оправдан, если вы считаете, что повторяющиеся Title и Description плохо отразятся на результатах в выдаче. Данная настройка закрывает страницы от индексации, но тем не менее переходить по ссылкам можно.
Путаница в использовании canonical и 301 редиректа. Встречаются случаи, когда вместо канонических URL используется 301 редирект. Казалось бы, действуют они схоже, перенаправляя робота на основную страницу. Но подменять их все же не стоит. 301 редирект переносит весь трафик и ссылочный вес на один URL, а при использовании атрибута rel=»canonical» страница все равно будет открываться и сможет получать трафик. Единственный нюанс – она не появится в индексе.
Выбор главной страницы сайта в качестве канонической. Одна из основных ошибок новичков – указать главную страницу сайта в качестве основной для всех остальных. В этом случае поисковые системы могут проиндексировать только главную, а другие страницы просто проигнорировать.
Закрытие канонической страницы от индексирования. Если канонический URL по любой причине недоступен для поискового робота, то он не будет проиндексирован и не сможет попасть в выдачу. Что же сделает бот? Он обратиться к другому доступному неканоническому URL.
Как проверить canonical
Проверка – важный этап настройки canonical. Чтобы посмотреть, какие страницы вы указали в качестве канонических и неканонических, воспользуйтесь сервисом Screaming Frog SEO Spider.
С помощью инструмента проверки URL можно оценить корректность работы canonical в Google (какую страницу он считает основной для определенного URL).
Для проверки в Яндексе можно использовать Вебмастер. Если все сделано правильно, и каноническая страница указана корректно, дубли исчезнуть из поиска. Для этого нужно зайти на вкладку «Индексирование» и перейти в раздел «Страницы в поиске». Все исключенные из результатов страницы будут находиться в блоке «Исключенные страницы».
Вопрос – ответ
И еще немного информации, чтобы до конца прояснить все возможные возникающие моменты.
Google ставит каноникал не на ваш ресурс, а на сторонний сайт – почему такое происходит?
Такая проблема может появиться по двум причинам.
- Сайт взломали злоумышленники. Они же проставили атрибут canonical в пользу другого ресурса. Если вы заметили странности и предполагаете такую ситуацию, то проверить это достаточно просто. Нужно зайти в исходный код страницы и определить, куда ведет тег. Если все указано корректно, нужно искать проблему в другом месте.
Как работают злоумышленники? Они могут добавлять на сайт код, выполняющий переадресацию 301 HTTP. Еще один вариант – вставка в HTML-документ или HTTP-заголовок элемента link с атрибутом rel=»canonical» и междоменной ссылкой в секции < head >. Из-за этого пользователь может быть направлен на спамный ресурс или сайт с вредоносным ПО. При этом боты Google могут не распознать подмену и выбрать URL, который указали злоумышленники.

- Контент с вашего сайта скопирован на более трастовый ресурс. В этом случае Google может посчитать источником информации не вас, а именно тот сайт. Но вы имеете право подать DMCA запрос на удаление контента.
Кража контента – проблема нередкая, а вот то, что алгоритмы Google отдают предпочтение другому ресурсу, разместившему чужой контент, – дело не такое частое. Но если такая проблема все же выявилась, и кто-то нарушил ваши авторские права, для начала можно обратиться к владельцу сервера этого сайта. Если проблему не удалось решить мирно, придется отправлять запрос в Google. Эта возможность регламентируется законом США «Об авторском праве в цифровую эпоху».
Как понять, какую страницу все же выбрать канонической?
Когда выбор слишком большой, при принятии решения стоит ориентироваться на несколько моментов:
- определить страницу среди дублей, которая индексируется в этот момент;
- оценить посещаемость всех страниц из группы дублей;
- подсчитать количество внешних и внутренних ссылок;
- определить страницу с наименьшей вложенностью URL.
Исходя из анализа данных характеристик, рекомендуется выбрать в качестве основной ту страницу, которая уже находится в индексе, отличается хорошей посещаемостью, имеет наибольшее количество ссылок и не самый длинный URL-адрес.
Можно ли не использовать canonical при наборе сайта верхним и нижним регистром?
Выше мы уже говорили, что одинаковые адреса, написанные в верхнем и нижнем регистре, поисковые боты могут посчитать разными версиями сайта. Поэтому предпочтительнее писать все URL в нижнем регистре. Чтобы указать системе делать именно так, можно не использовать атрибут rel=”canonical”, а сделать соответствующие записи в .htaccess‑файле сайта.
В качестве заключения
Атрибут rel=“canonical” можно по праву считать одним из наиболее полезных инструментов для поискового продвижения. С его помощью можно устранить проблему с дублированием контента и спорные ситуации в определении подходящей страницы для индексации. Кроме того, это позволяет эффективнее расходовать краулинговый бюджет.
Использовать тег canonical среди оптимизаторов стало признаком хорошего тона. Атрибут позволяет предупредить проблему даже тогда, когда дублирование или наличие схожего контента не предполагается.
Появление дублей возможно на страницах различного назначения, соответственно rel=”canonical” может использоваться в следующих случаях:
- для страниц сортировки (*sort, asc, desc, list=*);
- при наличии UTM-меток (utm_source, utm_term, utm_campaign, utm_medium);
- для страниц с GET-параметрами в URL;
- для дублей, появившихся в результате работы CMS;
- для страниц с похожим контентом, но разными URL-адресами;
- на страницах пагинации.
Самое главное здесь – правильно использовать и настроить атрибут. Только так можно добиться желаемого результата. Корректное использование rel=”canonical” позволяет ускорить индексацию ресурса и оказать положительное влияние на ранжирование продвигаемого сайта.