Файл robots.txt — это текстовый документ, который содержит инструкции для поисковых роботов о том, как индексировать страницы сайта. С помощью этого файла можно ограничить доступ к некоторым страницам сайта для роботов поисковых систем, что может снизить нагрузку на сервер и ускорить работу сайта.
Примечание: следует помнить, что ограниченные к индексации страницы могут по-прежнему появляться в поисковых результатах поиска. Чтобы предотвратить это, необходимо использовать директиву noindex в HTML-коде страницы или настроить HTTP-заголовок. Но не следует ограничивать доступ к таким страницам в файле robots.txt, так как поисковые робот могут не обнаружить ваши указания (см. подробнее в инструкции Яндекса).
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.

Требования к файлу robots.txt
Для правильного функционирования файла robots.txt на сайте, необходимо соблюдать некоторые требования. Роботы поисковых систем обрабатывают его только в том случае, если:
- размер файла не превышает 500 КБ,
- он имеет название robots.txt,
- расположен в корневом каталоге сайта,
- файл должен быть доступен для роботов, это означает, что сервер, на котором размещен сайт, должен отдавать HTTP-код со статусом 200 OK (проверить ответ сервера можно здесь).
Если файл не соответствует этим требованиям, сайт будет считаться открытым для индексирования.
Поисковые системы также поддерживают редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Важно понимать, что правильное управление файлом robots.txt может значительно повлиять на работу сайта и его видимость в поисковых результатах. Поэтому следует тщательно прорабатывать инструкции для роботов, чтобы достичь наилучших результатов.
Рекомендации по заполнению файла robots.txt
Яндекс поддерживает несколько директив, которые могут быть использованы в файле robots.txt для управления поведением роботов на сайте. Вот некоторые из них:
1. User-agent *: Эта директива указывает на робота, для которого действуют перечисленные в файле правила.
2. Disallow: Эта директива запрещает обход разделов или отдельных страниц сайта.
Примеры:
| User-agent: * |
| Disallow: / |
Такая запись запрещает всем роботам проводить индексацию сайта.
| User-agent: Yandex |
| Disallow: /private/ |
Данная запись применяется для запрета индексации для основного робота поисковой системы Яндекс только директории /private/.
3. Sitemap: Эта директива указывает путь к файлу Sitemap, который размещен на сайте. Эта директива межсекционная, т. е. где бы она ни была расположена в robots.txt, поисковые роботы ее обязательно учтут. Как правило, ее выносят в самый конец файла.
Робот обрабатывает эту директиву, запоминает и перерабатывает данные. Полученная информация будет основой при формировании следующих сессий загрузки страниц сайта.
Пример:
| User-agent: * |
| Allow: /catalog |
| sitemap: https://mysite.com/my_sitemaps0.xml |
| sitemap: https://mysite.com/my_sitemaps1.xml |
4. Clean-param. Дополнительная директива, предназначенная для роботов поисковой системы Яндекс. Она указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании.
Так выглядит описание стандартного синтаксиса этой директивы:
Clean-param: s0[&s1&s2&..&sn] [path]
В первом поле указаны параметры, которые не следует учитывать. Для их разделения используется символ «&». Во втором поле стоит префикс пути страниц, подпадающих под действие этого правила.
Пример:
| User-agent: * |
| Disallow: |
| Clean-param: id /forum.com/index.php |
Пример использования директивы Clean-param для некого форума, где движок сайта генерирует длинные ссылки и присваивает каждому пользователю персональный параметр id. Содержание страниц при этом остается неизменным. Данный файл robots.txt не дает попасть в индекс множеству фактически одинаковых страниц.
5. Allow: Эта директива разрешает индексирование разделов или отдельных страниц сайта.
6. Crawl-delay. Эта директива задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Кстати, роботы поисковой системы Яндекс умеют считывать дробные значения. В Google директива не учитывается.
Пример:
| User-agent: * |
| Disallow: /cgi |
| Crawl-delay: 4.1 # таймаут 4.1 секунды для роботов |
Рекомендуется использовать настройку скорости обхода в Яндекс Вебмастере вместо директивы Crawl-delay.

Примечание: Обратите внимание, что использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера. Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
#Не правильно: |
User-agent: * |
Disallow: /корзина |
Sitemap: сайт.рф/sitemap.xml |
#Правильно: |
User-agent: |
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 |
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml |
Наиболее часто используемые директивы – Disallow, Sitemap и Clean-param. Например, чтобы запретить ссылки из «Корзины с товарами», страниц встроенного на сайте поиска и панели администратора, в файле robots.txt можно указать следующее:
User-agent: * #указывает, для каких роботов установлены директивы |
Disallow: /bin/ # запрещает ссылки из "Корзины" |
Disallow: /search/ # запрещает ссылки страниц встроенного поиска на сайте |
Disallow: /admin/ # запрещает ссылки из панели администратора |
Sitemap: http://example.com/sitemap.xml # указывает роботу на XML-карту сайта |
| Clean-param: ref /some_dir/get_book.pl |
Обратите внимание, что роботы разных поисковых систем и сервисов могут по-своему интерпретировать директивы. Также стоит помнить, что робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Как составить файл robots.txt
Для начала, необходимо открыть текстовый редактор и создать новый файл, который должен называться robots.txt. Затем, в этом файле вы можете указать необходимые директивы.
Для того, чтобы проверить файл в Вебмастере, необходимо зайти в раздел «Инструменты» и выбрать опцию «Анализ robots.txt». Это поможет вам убедиться, что файл был составлен правильно и не содержит ошибок.
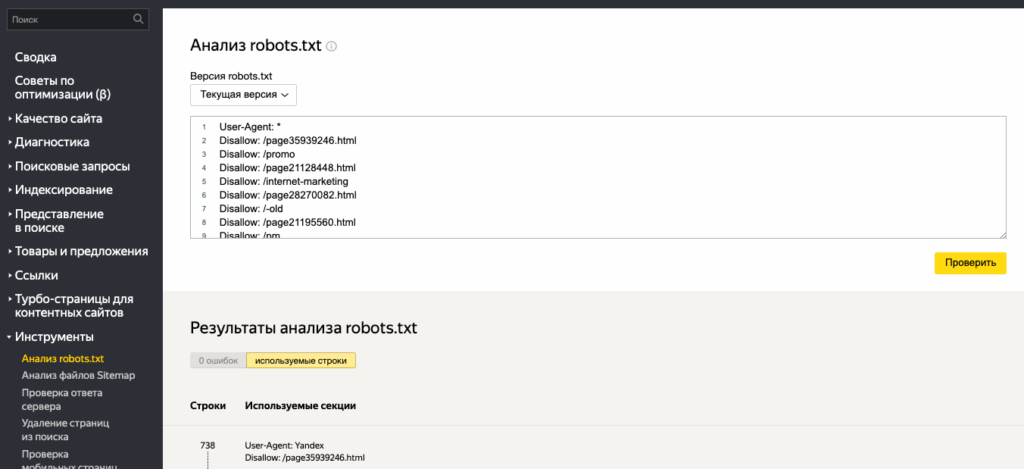
Далее, нужно разместить файл в корневой директории вашего сайта. Это обеспечит доступ к файлу всем поисковым системам и позволит им легко определить, какие страницы сайта необходимо индексировать, а какие нет.
Ниже приводится пример файла, который разрешает индексирование всего сайта для всех поисковых систем:
User-agent: *
Disallow:
Этот пример позволяет всем поисковым системам индексировать любые страницы на сайте. Однако, если вы хотите запретить индексирование некоторых страниц, то вам необходимо указать их в соответствующих директивах.
Спецсимволы
Внесение любых директив требует по умолчанию приписывать в конце спецсимвол «*». Таким образом, действие указания будет распространяться на все страницы или разделы сайта, которые начинаются с определенной комбинации символов. Для отмены действия по умолчанию нужно использовать специальный символ «$».
Согласно стандарту использования файла robots.txt, рекомендуется вставлять пустой перевод строки после каждой группы директив User-agent. Специальный символ «#» служит для размещения комментариев в файле. Роботы не учитывают содержание строки, размещенное за символом «#» до знака пустого перевода.
Пример:
| User-agent: Googlebot |
| Disallow: /pictures$ # запрещает ‘/pictures’, # но не запрещает ‘/pictures.html’ |
Как запретить индексацию сайта или его разделов
Зачем прятать информацию от поисковых роботов? Для продвижения в поиске важно показывать только полезную информацию, от публичного просмотра лучше скрыть технические и служебные страницы, дубли, ресурсы в разработке, конфиденциальную информацию. Для этого и используется описанная в начале статьи директива Disallow.
Пример:
| User-agent: * |
| Disallow: / # блокирует доступ ко всему сайту |
| User-agent: Yandex |
| Disallow: / bin # блокирует доступ к страницам, # которые начинаются с ‘/bin’ |