Поисковый робот (веб-паук или web crawler) — это программное средство, разработанное для автоматического обхода и анализа информации на веб-страницах. Он функционирует путем сканирования содержимого веб-сайтов и сбора данных, которые затем передаются поисковым системам или владельцам компаний.
Наиболее известными пользователями краулеров являются поисковые системы. Их веб-пауки проходят по доступным ссылкам, сканируют и анализируют содержимое веб-страниц, чтобы собрать информацию для обновления и пополнения базы данных поисковой машины.
Помимо HTML-страниц, такие краулеры также способны сканировать документы различных форматов, такие как Adobe PDF (.pdf), Microsoft Excel (.xls, .xlsx), Microsoft PowerPoint (.ppt, .pptx) и Microsoft Word (.doc, .docx). Это позволяет поисковым системам индексировать и предоставлять результаты поиска не только для веб-страниц, но и для различных типов файлов, что значительно расширяет доступность информации для пользователей.
Зачем нужен поисковый робот
Поисковые роботы играют ключевую роль в работе поисковых систем, являясь связующим звеном между доступным контентом в сети и пользователями. Без сканирования и добавления в базу данных поисковика веб-страница не будет отображаться в результатах поиска и будет доступна только по прямой ссылке.
Кроме того, роботы влияют на ранжирование страниц. Например, если краулер не может корректно просканировать веб-сайт из-за неизвестных ему API или функций JavaScript, это может привести к ошибкам при сканировании страниц и даже к их исключению из индекса. В результате на сервер поисковой системы могут отправляться страницы с ошибками, а часть контента может оказаться вне зоны обнаружения робота.
Поскольку поисковые системы используют специальные алгоритмы для анализа и ранжирования полученных данных с целью предоставления пользователям более релевантной информации, некачественные страницы или страницы с ограниченной доступностью для роботов могут оказаться в конце списка результатов поиска или даже вовсе быть незамеченными.
Как работает поисковый робот
Поисковый робот начинает свою работу с парсинга новых страниц или файлов для включения их в базу данных поисковой системы. Этот процесс обычно происходит автоматически, когда робот переходит по ссылкам с уже известных ему страниц или разделов сайта. Например, если на веб-сайте есть блог, робот будет регулярно проверять его на наличие новых записей, добавляя их в список для последующего сканирования.
Важно знать! Если на сайте присутствует файл sitemap.xml, который содержит карту сайта со списком всех доступных страниц и их приоритетов, робот будет регулярно считывать этот файл для получения ссылок на сканирование. Это позволяет эффективно управлять процессом индексации и обеспечить включение в поисковую базу всех страниц сайта.
Также возможна ручная передача конкретного URL для сканирования поисковому роботу. Для этого веб-мастер может подключить сайт к инструментам веб-мастера, таким как Яндекс.Вебмастер или Google Search Console, и вручную добавить ссылку на страницу, которую необходимо проиндексировать. Этот подход полезен в случаях, когда необходимо быстро добавить новую страницу в поисковую базу или управлять приоритетом индексации определенных URL.
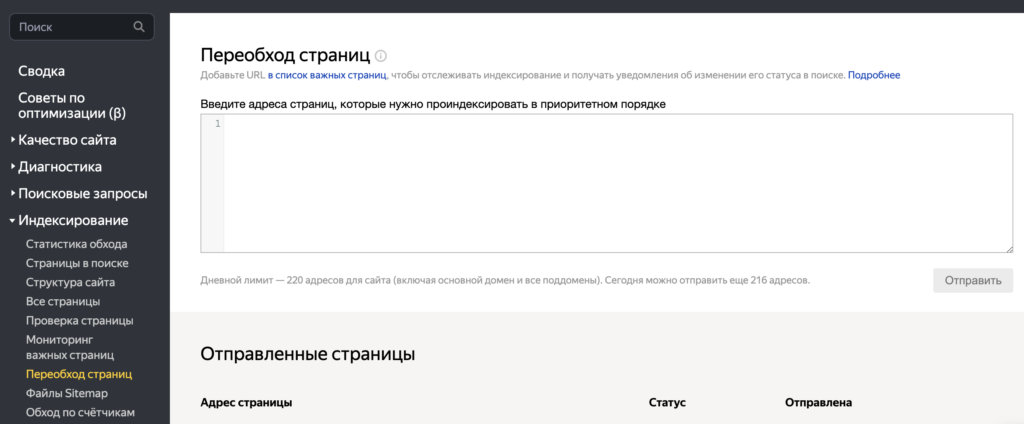
После обнаружения доступной страницы следующим шагом является её сканирование. Поисковый робот анализирует текстовое содержимое страницы, извлекает информацию из HTML-тегов и обрабатывает гиперссылки. Полученные данные затем загружаются на сервер для последующей обработки.
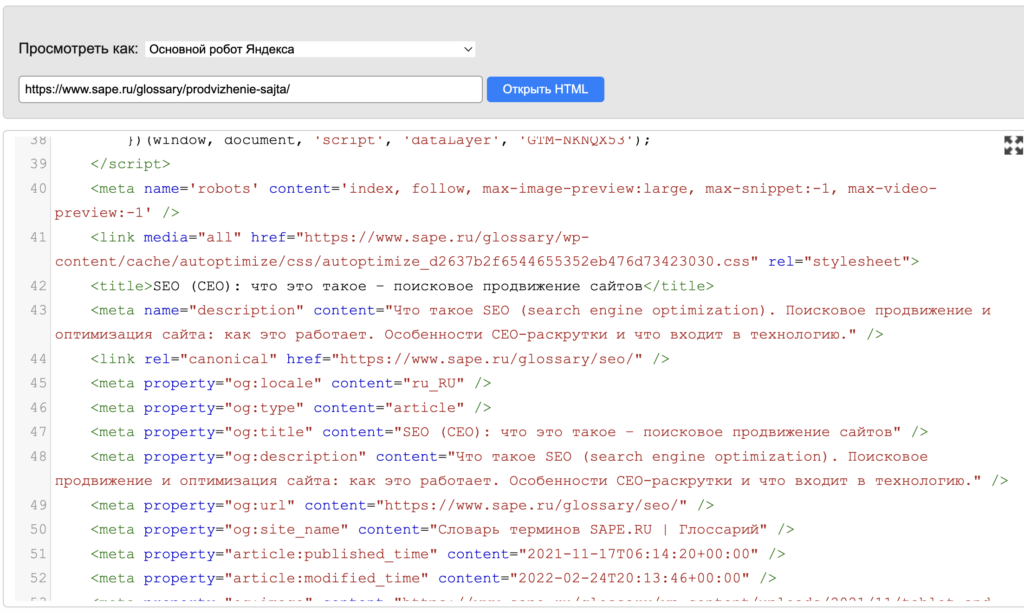
После этого содержимое страницы проходит через процесс очистки от лишних HTML-тегов и структурируется перед тем, как добавиться в базу данных поисковой машины, так называемый индекс. Фактическую индексацию выполняет специальный индексный робот, который может рассматриваться как часть или разновидность поискового робота.
Скорость индексации может различаться в зависимости от поисковой системы. Например, Яндекс обычно добавляет новые страницы в результаты поиска в течение нескольких дней, в то время как Google может индексировать их за несколько часов.
Важно знать! Если сайт новый и только начинает работу — поисковая система еще не знает о его существовании. В таком случае полный процесс сканирования и индексации может занять несколько месяцев.
Поисковые роботы не ограничиваются однократным посещением сайта. Они непрерывно отслеживают изменения на страницах и сообщают поисковой системе о удалении или перемещении уже проиндексированных страниц. Частота обновления и периодичность обхода зависят от объема трафика, размера и глубины сайта, а также от частоты обновления его содержимого.
Какие бывают поисковые роботы
Самые известные веб-пауки принадлежат к поисковым системам, и их главная задача состоит в добавлении и обновлении данных в результатах поиска. Помимо основных роботов, каждая поисковая система имеет специализированных агентов, которые занимаются загрузкой различных типов контента, таких как изображения, видео, новости и другие.
Google, например, имеет несколько веб-пауков-помощников:
- Googlebot-Image занимается поиском изображений,
- Googlebot-Video отвечает за видеоконтент,
- Googlebot-News обеспечивает актуализацию новостных списков.
В Яндексе также существуют отдельные пауки, которые сканируют интернет для различных сервисов, начиная от Яндекс.Маркета и заканчивая Яндекс.Аналитикой. Над обновлением поисковой системы работают два основных робота: основной и быстрый, известный под названием Orange. Каждый из этих пауков имеет свои функциональные особенности и предназначен для сбора определенного типа информации, чтобы обеспечить полноту и актуальность данных в поисковых результатах.
Важно знать! Ускоренное индексирование позволяет добавлять в поисковую выдачу файлы, которые были созданы всего лишь несколько минут назад. Это значит, что пользователи могут получать доступ к свежей и актуальной информации в режиме реального времени. Такие запросы часто включают онлайн трансляции, новостные и букмекерские сайты, а также другие ресурсы, предоставляющие важную информацию на текущий момент.
Отобранные страницы, прошедшие ускоренное индексирование, остаются доступными в специальной выдаче в течение трех дней. После этого они подлежат повторному индексированию основным роботом для размещения в общем каталоге поиска. Этот процесс обновления помогает обеспечить постоянную актуальность и релевантность поисковых результатов для пользователей.
Важно отметить, что ускоренное индексирование доступно только для ограниченного числа ресурсов, которые соответствуют определенным критериям. Например, обычный информационный или коммерческий веб-ресурс с разделом новостей не будет включен в ускоренную новостную индексацию.
Критерии для попадания в ускоренный индекс
- актуальность контента,
- частота обновлений,
- популярность ресурса и его авторитетность.
Ресурсы, которые предоставляют важную информацию в реальном времени, например, новостные агентства или спортивные сайты с актуальной информацией о событиях, обычно попадают в ускоренный индекс. Таким образом, для попадания в ускоренный индекс необходимо не только предоставлять новости, но и соответствовать определенным критериям, чтобы поисковые системы рассматривали ваш ресурс как достойный для включения в эту категорию.
У компаний Mail.ru, Bing, Yahoo, DuckDuckGo, Baidu и других также есть свои собственные веб-пауки, или краулеры. Они выполняют аналогичные функции по сканированию веб-страниц, сбору данных и обновлению поисковых баз данных.
User-Agent
Роботов, сканирующих веб-страницы для индексации и обновления поисковых баз данных, обычно называются «вежливыми». Они отличаются от обычных пользователей интернета тем, что не притворяются живыми пользователями и не взаимодействуют с сайтами так, как это делал бы обычный человек.
Это делается для того, чтобы облегчить отслеживание их активности при помощи аналитических инструментов. Каждый поисковый робот обычно имеет уникальное имя, называемое User-Agent, которое позволяет веб-серверам определить их идентификацию.
Использование уникальных идентификаторов User-Agent позволяет веб-мастерам легко отслеживать активность поисковых роботов на своих сайтах и управлять взаимодействием с ними через файл robots.txt или другие средства управления краулерами.
| Поисковый робот | User-Agent строка |
|---|---|
| Googlebot | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Bingbot | Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Yahoo! Slurp | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
| Yandex | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
| DuckDuckBot | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
| Baidu Spider | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| Sogou Spider | Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) |
| Exabot | Exabot Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
| MJ12bot | Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/) |
Это лишь небольшой набор из множества существующих поисковых роботов. Кроме того, стоит помнить, что роботы могут изменять свои User-Agent строки, поэтому эти данные могут быть неактуальными в будущем.
Роботы-парсеры
Помимо поисковых систем, сканированием и индексированием веб-страниц также занимаются различные сервисы аналитики и SEO. Например, Amazonbot сканирует интернет для улучшения внутренних сервисов и обучения поискового ассистента Алексы.
Среди популярных SEO-инструментов такие как Ahrefs Bot, Semrush Bot и Screaming Frog, которые собирают открытые данные для своих клиентов. С их помощью владелец веб-страницы или маркетолог может проверить сайты конкурентов, выявить технические проблемы собственных ресурсов и разработать стратегию продвижения.
Кроме того, существует множество так называемых «вредных» роботов. Они могут мимикрировать под пользовательские браузеры или копировать имена известных поисковых краулеров, чтобы парсить информацию с сайтов для дальнейшего коммерческого использования. На основе собранных ими данных создаются базы для проведения холодных звонков и email-рассылок. Эти «вредные» роботы могут наносить ущерб веб-сайтам, осуществляя несанкционированный сбор информации и нарушая правила использования ресурсов интернета.
Проблемы, которые могут возникнуть при работе поисковых роботов
Работа поисковых роботов может столкнуться с рядом проблем, которые могут негативно сказаться на индексации и доступности веб-сайтов:
- Неполная и медленная индексация сайтов. Сложная структура сайта или отсутствие явной перелинковки может затруднить роботам полный обход сайта. Это может привести к медленной индексации страниц, особенно если сайт содержит множество страниц и поддоменов.
- Ошибки в верстке и наличие дублей. Наличие ошибок в верстке или дублирование контента на страницах могут замедлить процесс индексации или даже привести к игнорированию страниц поисковыми системами.
- Повышенная нагрузка на сервер. Частые обращения поисковых роботов могут создать дополнительную нагрузку на серверы сайта, что может привести к перебоям в работе или временной недоступности ресурса.
- Утечка незащищенной информации. Если страницы с конфиденциальной информацией не защищены или не запрещены для индексации, поисковые роботы могут случайно индексировать эти данные и сделать их доступными в поисковой выдаче. Это может привести к утечке конфиденциальных данных пользователей, как это произошло в случае с поисковыми системами Яндекс и Google Docs.
Для предотвращения этих проблем рекомендуется внимательно следить за структурой и контентом сайта, обеспечивать защиту конфиденциальной информации, а также настраивать серверы для эффективной обработки запросов поисковых роботов.
Как повлиять на работу роботов
Вот несколько методов, которые могут повлиять на работу поисковых роботов и улучшить процесс индексации и ранжирования вашего сайта в поисковых системах:
- Техническая оптимизация сайта. Работа по устранению проблем с хостингом, настройка редиректов, удаление неработающих ссылок и дублей страниц помогает повысить качество вашего сайта в глазах поисковых роботов. Это также ускоряет процесс индексации и улучшает позиции вашего сайта в выдаче поиска.
- Использование систем веб-аналитики. Внедрение систем веб-аналитики, таких как Google Analytics, Яндекс.Метрика и Рейтинг@Mail.ru, помогает поисковым сервисам более точно оценивать качество и активность вашего сайта. Это может положительно сказаться на его ранжировании в поисковой выдаче.
- Подключение к инструментам для вебмастеров. Использование инструментов Google Search Console и Яндекс.Вебмастер позволяет вам более активно контролировать процесс индексации вашего сайта и исправлять технические ошибки, которые могут мешать его видимости в поисковой выдаче.
Применение этих методов поможет оптимизировать ваш сайт для работы с поисковыми роботами, что в свою очередь способствует улучшению его позиций в поисковой выдаче и привлечению целевой аудитории.
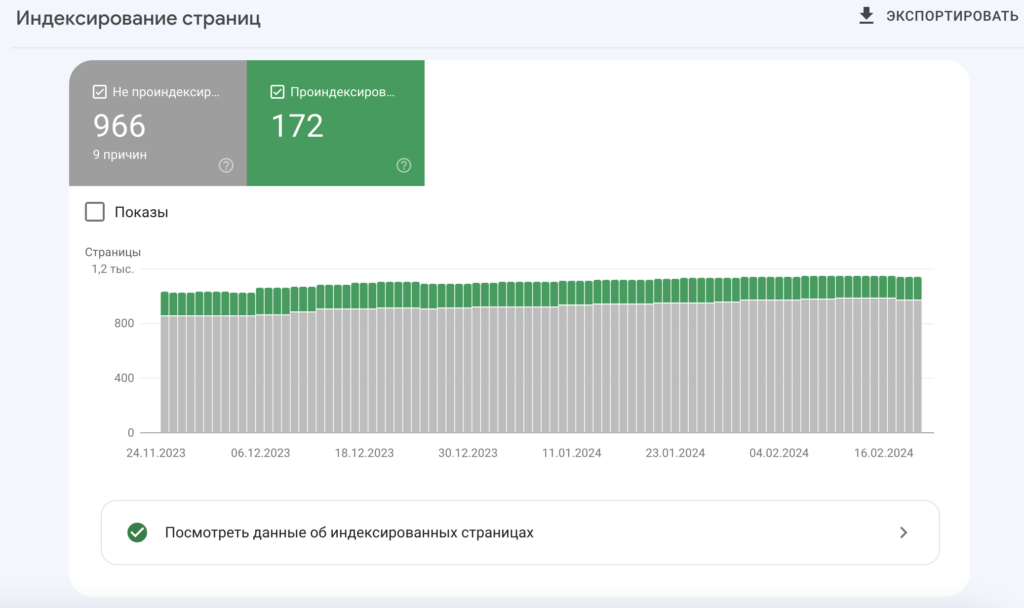
Повышение эффективности обхода сайта поисковыми роботами
Файлы sitemap и robots.txt играют важную роль в оптимизации процесса индексации веб-ресурса поисковыми роботами.
- Файл sitemap.xml. Этот файл представляет собой список всех доступных страниц вашего сайта, который вы предоставляете поисковым системам для сканирования и индексации. Добавление новых страниц или обновление существующих в sitemap.xml позволяет уведомить поисковые роботы о изменениях на вашем сайте и ускорить процесс индексации.
Кроме того, с помощью тегов priority и changefreq в файле sitemap.xml можно указать поисковым роботам о частоте обновления контента и приоритете индексации каждой страницы. Это помогает поисковым системам более эффективно сканировать и индексировать ваш сайт.
- Файл robots.txt. Этот файл предоставляет инструкции поисковым роботам о том, какие страницы или разделы сайта должны или не должны индексироваться. Это позволяет управлять тем, какие страницы будут видны в поисковой выдаче, и исключать нежелательные страницы, такие как страницы с конфиденциальной информацией или временные страницы.
Например, вы можете использовать файл robots.txt, чтобы запретить роботам индексировать временные страницы или страницы с дублирующимся контентом, что поможет сосредоточить индексацию на наиболее важных страницах вашего сайта.
В целом, использование файлов sitemap.xml и robots.txt является важным элементом SEO-оптимизации, который помогает улучшить процесс индексации вашего сайта поисковыми системами и повысить его видимость в поисковой выдаче.
Один из основных примеров использования robots.txt — это исключение от индексации страниц, содержащих личные данные пользователей, такие как личные кабинеты, формы и корзины. Это помогает предотвратить утечку конфиденциальной информации через поисковые системы.
Важно помнить! Файл robots.txt является только рекомендацией, а не запретом для поисковых роботов. Некоторые роботы могут проигнорировать эти правила, поэтому дополнительно рекомендуется использовать теги noindex для страниц, содержащих конфиденциальные данные. Эти теги сообщают поисковым системам, что страницы не должны быть индексированы, даже если к ним есть доступ через ссылки на сайте. Таким образом, это обеспечивает дополнительный уровень защиты конфиденциальности данных пользователей.
Главные мысли коротко
Что такое поисковый робот и как он работает:
- Поисковые роботы сканируют веб-страницы и передают данные поисковой системе или владельцу компании.
- Роботы находят и индексируют страницы автоматически, используя ссылки с известных разделов сайта.
- Роботы также отслеживают изменения и сообщают поисковой машине об удалении или перемещении проиндексированных страниц.
- Существуют разные типы роботов, включая специализированных для скачивания изображений, видео и новостей.
- Поисковые системы и сервисы аналитики и SEO имеют своих роботов для сканирования и индексирования страниц.
- Проблемы, которые могут возникнуть при работе поисковых роботов: неполная и медленная индексация, повышенная нагрузка на серверы и утечка незащищенной информации.
- Устранение проблем хостинга, настройка редиректов и удаление неработающих ссылок могут повысить шансы на быструю индексацию и размещение сайта на первой странице поисковой выдачи.